2. LDAP Concepts & Overview
If you already understand what LDAP is, what it is good for, Schemas, objectClasses, Attributes, matchingRules, Operational objects and all that jazz - skip this section. But if you are going to do anything except blindly follow HOWTOs you must understand most of this stuff.
LDAP and X.500 are feet deep in terminology. Some terminology is important, some is just fluff. We have created a glossary to jog your memory. We introduce terms either because they are important or because they are frequently used in the literature.
2.1 A Brief History of LDAP
2.2 LDAP Overview
2.3 LDAP vs. RDBMS
2.3.1 LDAP Usage Summary
2.4 LDAP Data (Object) Model
2.4.1 Object Tree Structure
2.4.2 Object Classes
2.4.3 Attributes
2.4.4 Describing the Tree by Adding (Data) Entries
2.4.5 Navigating the Tree
2.5 LDAP Replication and Referrals
2.5.1 Referrals
2.5.2 Replication
A brief Note about case sensitivity in LDAP: It's confusing - well, we found it confusing. Truth be told we find a lot of things confusing. The only case sensitive things in LDAP are passwords and the contents of certain (very obscure) attributes based on their matchingRule. Period. You will see both in this and other documentation: objectclasses or objectClasses and even ObjectClasses. They all work. Period. And you have enough to worry about in the first six years of learning LDAP (just kidding, it will only take four years) to get in a sweat every time you approach a keyboard in case you mistype the name of something. So, while it may be good practise to use that Camel Case notation the sun will not fall out of the sky if you forget.
The D in LDAP: Officially the D in LDAP stands for Directory - Lightweight Directory Access Protocol. Mostly this came about because of the historic beginnings of LDAP (and its predecessor DAP) which focussed on classic white-page directory style applications for email. However, terminology can be self-limiting. Make no mistake, LDAP is about Data access and if the term Directory limits your thinking because of existing mental models of directories (it certainly did for us - there again perhaps we are just mentally limited), substitute the term Data as in Lightweight Data Access Protocol in your mind when thinking about LDAP. But keep it to yourself. Heaven forfend that you break the rules.
2.1 A Brief History of LDAP
Once upon a time, in the dim and distant past (the late 70's - early 80's) the ITU (International Telecommunication Union) started work on the X.400 series of email standards. This email standard required a directory of names (and other information) that could be accessed across networks in a hierarchical fashion not dissimilar to DNS for those familiar with its architecture.
This need for a global network based directory led the ITU to develop the X.500 series of standards and specifically X.519, which defined DAP (Directory Access Protocol), the protocol for accessing a networked directory service.
The X.400 and X.500 series of standards came bundled with the whole OSI stack and were big, fat and consumed serious resources. Standard ITU stuff in fact.
Fast forward to the early 90's and the IETF saw the need for access to global directory services (originally for many of the same email based reasons as the ITU) but without picking up all the gruesome protocol (OSI) overheads and started work on a Lightweight Directory Access Protocol (LDAP). LDAP was designed to provide almost as much functionality as the original X.519 standard but using the TCP/IP protocol - while still allowing inter-working with X.500 based directories. Indeed, X.500 (DAP) inter-working and mapping is still part of the IETF LDAP series of RFCs.
A number of the more serious angst issues in the LDAP specs, most notably the directory root naming convention, can be traced back to X.500 inter-working and the need for global directories.
LDAP - broadly - differs from DAP in the following respects:
- TCP/IP is used in LDAP - DAP uses OSI as the transport/network layers
- Some reduction in functionality - obscure, duplicate and rarely used features (an ITU speciality) in X.519 were quietly and mercifully dropped.
- Replacement of some of the ASN.1 (X.519) with a text representation in LDAP (LDAP URLs and search filters). For this point alone the IETF incurs our undying gratitude. Regrettably, much ASN.1 notation still remains.

2.2 LDAP Overview
Technically, LDAP is just a protocol that defines the method by which directory data is accessed. Necessarily, it also defines and describes how data is represented in the directory service (the Data (Information) Model). Finally, it defines how data is loaded (imported) into and saved (exported) from a directory service (using LDIF). LDAP does not define how data is stored or manipulated. Data storage and access methods are automagical processes as far as the standard is concerned and are generally handled by back-end modules (typically using some form of transaction database) within any specific LDAP implementation.
LDAP defines four models which we list and briefly describe - you can then promptly forget them since they bring very little to the understanding of LDAP.
Information Model: We tend to use the term Data Model, in our view a more intuitive and understandable term. The Data (or Informational) Model defines how the information or data is represented in an LDAP enabled system - this may, or may not, be the way the data is actually stored on physical media since such grubby details lie outside the scope of the LDAP standards as described above.
Naming Model: This defines all that 'dc=example,dc=com' stuff that you stumble across in LDAP systems. We stick pretty much to the specifications here because the terms are so widely used.
Functional Model: When you read, search, write or modify the LDAP you are using the Functional Model - yipee!
Security Model: You can control, in a very fine-grained manner, who can do what to which data. This is complex but powerful stuff. We progressively introduce the concepts and have dedicated a specific chapter to it. To begin with - forget security. You can always go back and retro-fit security in LDAP. Where you cannot retro-fit, we reference security implications in the text. This model also encompasses wire-level security such as TLS/SSL. Good, solid, mind numbing stuff.
The scope of the LDAP standards is shown in the diagram below. The red stuff (1,2, 3, 4) is defined in the protocol (the various RFCs that define LDAP). What happens inside the black boxes (or in this case the green, yellow and mauve boxes) and on the black line to the Database(s) (5) is 'automagical' and outside the scope of the standards.
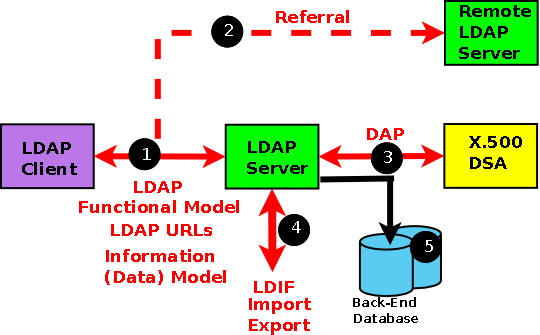
Each component is briefly described here, in a bit more detail below and in excruciating detail in subsequent chapters. But there are four important points first:
LDAP does not define how data is stored, only how it is accessed. BUT most LDAP implementations do use a standard database as a back-end and indeed OpenLDAP offers a choice of back-end database support.
When you talk to an LDAP server you have no idea where the data comes from: in fact the whole point about the standard is to hide this level of detail. In theory the data may come from one OR MORE local databases or one OR MORE X.500 services (though these are about as rare as hen's teeth these days). Where and how you access the data is an implementation detail and is only important when you define the operational configuration of your LDAP server(s).
Keep the two concepts - access to the LDAP service and operation of the LDAP service - very clearly separate in your mind. When you design a directory based system figure out what you want it to do (the data organization) and forget the implementation. Then figure out as a second phase where the data is and how and where you want to store it - during LDAP operational configuration.
A number of commercial database products provide an LDAP view (an LDAP wrapper or an LDAP abstraction) of relational or other database types.
2.3 LDAP vs. Database
LDAP is characterized as a write-once-read-many-times service. That is to say, the type of data that would normally be stored in an LDAP service would not be expected to change on every access. To illustrate: LDAP would not be suitable for maintaining banking transaction records since, by their nature, they change on almost every access (transaction). LDAP would, however, be eminently suitable for maintaining details of the bank branches, hours of opening, employees, and so on which change far less frequently.
Read Optimized
It is never clear in the phrase write-once-read-many-times just how many is many?
Where is the line between sensible use of LDAP as opposed to a classic transaction oriented relational database, for example, SQLite, MySQL, PostGreSQL. If we update every second access, is this a sensible LDAP application, or should it be every 1,000 or 1 million times.
The literature is a tad sparse on this topic and tends to stick with slam-dunk LDAP applications like address books which change, perhaps, once in living memory.
There is no simple answer but the following notes may be useful:
The performance hit during writes lies in updating the indexes. The more indexes (for faster reading) the less frequently you want to update the directory. Read:write ratios of 1,000:1 or higher for heavily read optimised LDAP directories, 500:1 or higher for modestly optimised indexing (2 or 3 indexes) are sensible.
LDAP Replication generates multiple transactions for every update so you want the lowest practical update load - Read:Write ratios of 500:1 or higher should be targeted.
If data volumes are large (say > 100,000 entries) the time to update even a small number of indexes may be serious so you want to keep updates as low as practical - Read:write ratios of 10,000:1 or higher.
If data volumes are relatively small (say < 1,000 records which constitute many security based LDAP uses), indexes modest (2 or 3 at most) and no replication is being used we see no inherent reason why you could not use LDAP in a form which approaches a transaction based system, that is, Read:write ratios between 5:1 and 10:1. If replication is added then perhaps 50:1 - 100:1 are more appropriate.
We suspect the real answer to this question, with apologies to the memory of the late, lamented Douglas Noel Adams, is that the optimum ratio of reads to writes is - 42!
Visibility of Data Organization
The primitives (LDAP protocol elements) that are used to access LDAP enabled directories use a model of the data that is (may be) abstracted from its physical organization. The primitives assume an object data model without being aware of the actual structure of the data. Indeed the relative simplicity of LDAP comes from this characteristic. The specific LDAP server implementation will, in its back-end function, perform the LDAP primitive to physical data organization mapping in a completely automagical way.
This is in marked contrast to, say, SQL in which the SQL queries used to interrogate the data have complete and detailed knowledge of the data structures and organization into tables, joins, primary keys and so on.
Data Synchronisation and Replication
Relational and transactional databases go to extreme lengths to ensure that data is consistent during write/update cycles using such techniques as transactions, locking, roll-back and other methods. It is a vital and necessary requirement for this type of database technology. This extreme form of data synchronisation also persists when the data is replicated on multiple hosts or servers. All views of the data will be consistent at all times.
The data in a master LDAP server and its slaves (or its peer in a multi-master environment) use a simple asynchronous replication process. This has the effect of leaving the master and slave (or peer) systems out of data synchronisation during the replication cycle. A query to the master and slave during this (usually very short) period of time may yield a different answer. If the world will come to shuddering halt as a consequence of this discrepancy, LDAP is not suitable for this application. However, if Bob Smith is shown in the accounting department on one LDAP server and in the sales department on another for a few seconds or less, who cares? A surprising number of applications fall into this category.
Note: Modern LDAP implementations, especially those that support Multi-master configurations, have increasingly become more sophisticated in replicating updates. Additionally, high-speed communication networks permit significantly faster replication operations. These issues, however, simply reduce the time window during which any two systems may be out-of-sync they do not eliminate the out-of-sync behaviour of LDAP - even though it is typically sub-second in most modern implementations.
2.3.1 LDAP Usage Summary
So what are LDAP (Directory) advantages and why would any sane human being use a directory?
Before attempting to answer the question let's dismiss the tactical issue of performance. In general, RDBMS systems are still significantly faster than LDAP implementations. This is changing with the development of second generation Directory Servers but while RDBMS will always remain faster than LDAP the gap is declining significantly to the point where, assuming you compare like with like (a measured network initiated transaction), the differences will become increasingly trivial. Unless, of course, you update a highly indexed attribute on every operation - in which case you deserve everything you (don't) get.
So why use LDAP? Here is our list of key characteristics which make the (currently) high level of pain worthwhile.
LDAP provides a remote and local data access method that is standardized. It is thus possible to replace the LDAP implementation completely without affecting the external interface to the data. RDBMS systems mostly implement local access standards, such as SQL, but remote interfaces are always proprietary.
Because LDAP uses standardized data access methods, LDAP Clients and Servers may be sourced (or developed) independently. By extension of this point LDAP may be used to abstract the view of data contained in transaction oriented databases, say for the purpose of running user queries, while allowing the user to transparently (to the LDAP queries) change the transactional database supplier.
LDAP provides a method whereby data may be moved (delegated) to multiple locations without affecting any external access to that data. By using referral methods LDAP data can be moved to alternate LDAP servers by changing operational parameters only. Thus, it is possible to construct distributed systems, perhaps with data coming from separate autonomous organizations, while providing a single, consistent, view of the data to its users.
LDAP systems can be operationally configured to replicate data to one or more LDAP servers or applications without adding either code or changing the external access to that data.
These characteristics focus exclusively on the standard nature of LDAP data access and do not consider the ratio of reads to writes which, as noted above, depend on the number of operational indices maintained. They implicitly discount the use of LDAP systems for transaction processing - though there are signs that some LDAP implementations are looking toward such capabilities.
2.4 LDAP Information (Data or Object) Model
LDAP enabled directories use a data model that represents the data as a hierarchy of objects. This does not imply that LDAP is an object-oriented database. As pointed out above, LDAP itself is a protocol that allows access to an LDAP enabled service and does not define how the data is stored - but the operational primitives (read, delete, modify) operate on a model (description/representation) of the data that has object-like characteristics (mostly).
2.4.1 Object Tree Structure
This section defines the essence of LDAP. If you understand this section and the various terms and relationships involved you understand LDAP.
Data is represented in an LDAP system as a hierarchy of objects, each of which is called an entry. The resulting tree structure is called a Directory Information Tree (DIT). The top of the tree is commonly called the root (a.k.a base or the suffix).
Each entry in the tree has one parent entry (object) and zero or more child entries (objects). Each child entry (object) is a sibling of its parent's other child entries.
Each entry is composed of (is an instance of) one or more objectClasses. Objectclasses contain zero or more attributes. Attributes have names (and sometimes abbreviations or aliases) and typically contain data (at last!).
The characteristics (properties) of objectClasses and their attributes are described by ASN.1 definitions.
Phew! You now know everything there is to know about LDAP. The rest is just detail - there is quite a lot of detail. But this is the core of LDAP.
The diagram below illustrates these relationships:
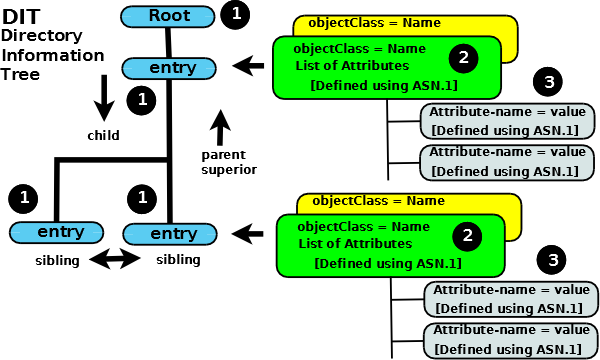
LDAP DIT Information (Data) Model
Summary:
Each Entry (1) is composed of one or more objectClasses (2)
Each objectClass (2) has a name and is a container for attributes (its definition identifies the attributes it may or must contain)
Each Attribute (3) has a name, contains data, and is a member of one or more objectClass(es) (2)
When the DIT is populated each entry will be uniquely identified (relative to its parent entry) in the hierarchy by the data it contains (in its attributes which are contained in its objectClasses(es)).
Now, take the rest of the day off and celebrate.
2.4.2 ObjectClasses
Objectclasses are, essentially, containers for attributes and are described using ASN.1 definitions. Each objectClass has a unique name. There are a confusing number of pre-defined objectclasses, each of which contains bucket-loads of attributes suitable for almost all common LDAP implementations. It goes without saying, however, that in spite of all those pre-defined objectClasses, the one you really, really need is never there! objectclasses have three more characteristics:
The objectclass defines whether an attribute member MUST (mandatory) be present or MAY (optional) be present.
Each objectclass has a type which may be STRUCTURAL, AUXILIARY or ABSTRACT (covered in detail in the next Chapter). At this stage it's enough to know that there must be one, and only one, STRUCTURAL objectClass in an entry and that there may be zero or more AUXILIARY objectClasses.
An objectclass may be part of a hierarchy in which case it inherits all the characteristics of its parent objectclass(es) (including all its contained attributes).
objectClasses are containers and control what attributes can get added to each entry but otherwise tend to stay in the background as far as accessing and interrogating (searching) the DIT is concerned. Attributes and entries are the really visible elements.
An incomplete browsable list of the most common objectClasses and their attributes.
More on objectClasses (a lot more) - only take the link if you are comfortable with this stuff (we'll get to it in the next chapter anyway) - otherwise continue reading here.
Uniqueness: Every name used in LDAP is unique. Each objectClass has a unique name, but it goes further than that. The unique objectClass name (or the name of any other LDAP thingy) is also a unique-in-LDAP name. There is (we will meet it later) an objectClass with the unique name of person, but it is also a unique-in-LDAP name. There is no attribute named person (or any other object type for that matter).
2.4.3 Attributes
Each attribute has a unique name (and shortform or alias) and normally contains data. Attributes are always associated with (are members of) one or more ObjectClasses. Attributes have a number of interesting characteristics:
All attributes are members of one, or more, objectclass(es)
Each attribute defines the data type (keyword is SYNTAX) that it may contain.
Attributes may be part of a hierarchy, in which case the child attribute inherits all the characteristics of the parent attribute. In the case of attributes a hierarchy is used to simplify and shorten the attribute definitions (in ASN.1) where many attributes share common properties such as maximum length or whether they are, or are not, case sensitive, and so on, it has no other significance.
Attributes can be optional (keyword is MAY) or mandatory (keyword is MUST) as described in the ASN.1 definitions for the objectclass of which they are a member. An attribute may be optional in one objectclass and mandatory in another. It is the objectclass which determines this property.
One sees apparently random attributes being picked up from all over the place in the documentation - it's confusing at first but comes from the optional characteristic of most attributes. It allows a 'pick-n-mix' approach to populating an entry. Find the attribute you want, find the objectclass of which it is a member (there may be more than one), and hope that all the other attributes that you don't want to use in the objectclass are optional! Try browsing here to get a feel for this.
Attributes can be SINGLE or MULTI valued (as described in their ASN.1 definitions). SINGLE-VALUE means that only one data value may be present for the attribute. MULTI-VALUE means the attribute can appear multiple times in an entry/object class with different data values. If the attribute describes say, an email address, there can be one, two or 500 definitions of the attribute each with a different mail address (it is multi) - this is one of a number of methods of dealing with email aliases in directory designs. The default for an attribute is MULTI-VALUE (allow multiple values).
Attributes have names and sometimes an alias (as described in their ASN.1 definitions), for example, the attribute with a name of cn is a member of the objectClass named person (and many others) and has an alias name of commonName. Either commonName or cn may be used to reference this attribute.
At each level in the hierarchy the data contained in an attribute can be used to uniquely identify the entry. It can be any attribute in the entry. It can even be a combination of two or more attributes.
The attribute value(s) selected to contain the unique'ish data is sometimes called the naming attribute(s) or the Relative Distinguished Name (RDN) - but more on that stuff later in this section.
Browse some common objectClasses and attributes. If it all looks pretty scary at this stage just forget you took the link and carry on reading.
More on Attributes (a lot more) - only take the link if you are comfortable with this stuff (we'll get to it in the next chapter anyway) - otherwise continue reading here.
2.4.4 Describing the Tree by Adding (Data) Entries
Eventually we want to slap some data into our directory and actually use the stupid thing.
Describing the tree structure and initial population of data is performed by adding entries (with their associated objectClasses and attributes) starting from the root of the DIT and progressing down the hierarchy. Thus, a parent entry must always have been added before attempting to add any child entries.
Entries are composed of one or more objectClasses (only one STRUCTURAL objectClass, but zero or more AUXILIARY objectClasses) and these objectClasses act as a container for attributes. Attributes contain data, not objectClasses.
We previously defined that when the DIT is created/populated each entry will be uniquely identifiable (relative to its parent entry) in the hierarchy. The only unique element in any data structure is the data. To uniquely identify an entry we need to identify its data content. The data content is defined in an attribute (which is contained by an objectClass) so we need to identify the attribute that contains the data that is unique. Recall that many attributes can be multi-valued - they can appear multiple times in an entry/objectClass with a different data content - so to create an absolutely, no doubt about it, uniqueness we need to identify both the attribute and the data it contains. This is done using an attribute-name=value (or data) format which, in the gruesome LDAP terminology, is termed an Attribute Value Assertion (AVA).
To illustrate, if the unique data in this entry (at this level in the hierarchy) is the word fred (OK it's a lousy example and pretty unlikely to be unique - but in Uzbekistan?) which is contained in an attribute whose name is cn then our AVA (Attribute Value Assertion) becomes cn=fred which we could, in this case, alternatively write as commonName=fred (the cn attribute has an alias name of commonName) if we were feeling either energetic (or stupid).
Now, it is possible that cn=fred is not absolutely unique (is that chuckling we hear in the background) so cannot be used as a unique identifier for this entry. We can either change our chosen value (there may be multiple cn=value entries in this entry to choose from) or change our chosen attribute (sn=de Gamma might work pretty well - except in Portugal of course). Alternatively, we can choose to use a second AVA to ensure uniqueness. In this case we will keep our cn=fred but add an AVA of drink=tamarind juice (to introduce an element of the exotic into the ridiculous). In this case the unique value would be written as cn=fred+drink=tamarind juice. Bound to be unique.
Adding entries may be done in a variety of ways, one of which is using LDAP Data Interchange Files (LDIF) which are fully described in a later chapter. LDIFs are textual files that describe the tree hierarchy - the Directory Information Tree (DIT) - and the data to be added to each attribute. The following is a simple example of an LDIF file which sets up a root DN (dc=example,dc=com) and adds a three child entries under a people entry.
Notes:
It is not important to understand what the values in this LDIF file do at this stage. Chapter 5 (samples) covers the details of setting up LDIF files and Chapter 8 explains LDIF files in painful detail. It is enough, at this stage, to know that LDIF files can be used to set up the DIT and that LDIF files look like the one below and that it sets up a DIT with the structure shown in diagram 2.4.4-1.
Adding LDAP entries may also be done using an LDAP client such as a general purpose LDAP Browser (see also LDAPBrowser/Editor) or a specialized application.
version: 1
## version not strictly necessary (and some implementations reject it) but generally good practice
## DEFINE DIT ROOT/BASE/SUFFIX ####
## uses RFC 2377 (domain name) format
## dcObject is an AUXILIARY objectclass and MUST
## have a STRUCTURAL objectclass (organization in this case)
# this is an ENTRY sequence and is preceded by a BLANK line
dn: dc=example,dc=com
dc: example
description: The best company in the whole world
objectClass: dcObject
objectClass: organization
o: Example, Inc.
## FIRST Level hierarchy - people
# this is an ENTRY sequence and is preceded by a BLANK line
dn: ou=people, dc=example,dc=com
ou: people
description: All people in organisation
objectClass: organizationalUnit
## SECOND Level hierarchy - people entries
# this is an ENTRY sequence and is preceded by a BLANK line
dn: cn=Robert Smith,ou=people,dc=example,dc=com
objectclass: inetOrgPerson
cn: Robert Smith
cn: Robert
sn: Smith
uid: rsmith
mail: robert@example.com
mail: r.smith@example.com
ou: sales
## SECOND Level hierarchy - people entries
# this is an ENTRY sequence and is preceded by a BLANK line
dn: cn=Bill Smith,ou=people,dc=example,dc=com
objectclass: inetOrgPerson
cn: Bill Smith
cn: William
sn: Smith
uid: bsmith
mail: bill@example.com
mail: b.smith@example.com
ou: support
## SECOND Level hierarchy - people entries
# this is an ENTRY sequence and is preceded by a BLANK line
dn: cn=John Smith,ou=people,dc=example,dc=com
objectclass: inetOrgPerson
cn: John Smith
sn: smith
uid: jsmith
mail: jim@example.com
mail: j.smith@example.com
ou: accounting
Important Note: The lines in the above LDIF file beginning with 'dn:' essentially tell the LDAP server how to structure or place the entry within the DIT (they are explained further in the following section). In general, it does not matter what attribute value is used for this purpose as long as the 'dn:' is unique. The above example has chosen to use "dn: cn=Robert Smith, ou=people, dc=example, dc=com" in the first entry for the SECOND level (third entry in the LDIF file) for this purpose. It could equally have been, say, "dn: uid=rsmith, ou=people, dc=example, dc=com". LDAP searching can be used with any combination of attributes and can thus find entries irrespective of the 'dn:' value used to create it. However, if the entry is going to be used for user authentication, say, logon or Single Sign-On type use, the 'dn:' value becomes extremely important and defines the logon (or Bind DN in the jargon) identifier which would typically be a uid). This entry name is sometimes (especially in the context of LDAP used within Microsoft's AD) referred to as a Principal DN though this term is not used within the LDAP standards definitions. For more on this topic.
If the above note reads like gobbledegook then forget it at this moment. It's all covered in nauseating detail much later.
We'll explain about LDIF files later as we need them but the above LDIF sets up the structure below:
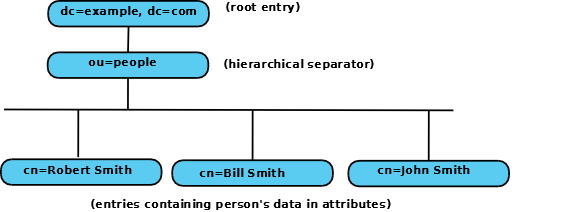
Diagram 2.4.4-1: DIT structure created by the LDIF file
Once the DIT is up and running, further data may be added using LDIF, an LDAP Browser, a web or other application interface.
Data can be exported (saved) for backup or other purposes using LDIF files.
2.4.5 Navigating the Tree
Having gotten data into our Tree (DIT) we would now - normally - like to use it!
To do that we have to send commands (read, search, modify etc.) to the LDAP server, and in order to do that we have to be able to tell the LDAP server where the data is (for a write) or roughly where it is (for a search/read).
In short we have to navigate (or crawl around) the directory.
But first, let's get some more essential terminology out of the way.
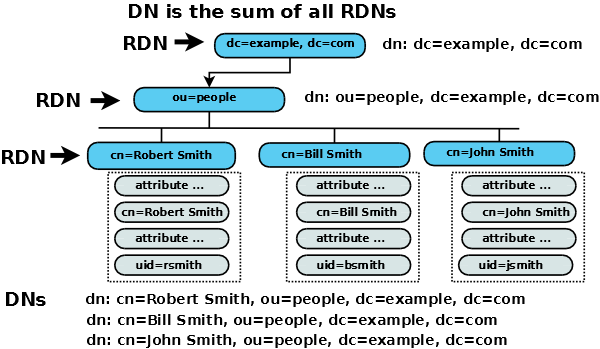
In the previous section we defined that each entry must be uniquely identifiable (relative to its parent) using a single (or multiple) AVA (Attribute Value Assertion), for example, cn=fred or from the example above cn=Robert Smith. Now it follows from the rule that each identifying AVA (or multiple AVA) must be unique (relative to its parent) in the hierarchy that the path to any entry at any level must also be unique (it is the sum of individually unique entries).
The LDAP terminology that describes this addressing stuff pushes the english language to its limits. So far we have used the term unique, a reasonably common and well understood english word, to describe the AVA of the entry. Now we could also have said that each entry has a different name, in addition (groan) we could also have said, somewhat tortuously, that each entry was, by virtue of its unique identification, distinguished from its siblings. You got it. The great and good in their infinite wisdom decided to use the word Distinguished.
So the AVA, for example, cn=Robert Smith, which uniquely identifies an entry is termed the Relative Distinguished Name (RDN - Relative to its parent). The path from the root (a.k.a base or suffix) of the DIT to the entry is the sum of all the RDNs (joined by a , (comma) and in low to high (left to right) order) is termed the Distinguished Name (DN). Wow. Whatever your views of the merits, or otherwise, of LDAP and X.500 the ability of the standard group to generate unique (or distinguished) terminology is beyond question.
To illustrate, in our example DIT the path from the root to the entry uniquely described by the AVA cn=Robert smith goes from (RDN) dc=example,dc=com through (RDN) ou=people ending with (RDN) cn=Robert Smith. The DN would be written as cn=Robert Smith,ou=people,dc=example,dc=com.
Three additional points before you collapse from exhaustion.
Recall that we can use multiple AVAs to create a unique indentity so an RDN could comprise cn=Robert Smith + uid=rsmith (typically known as a multi-value RDN). Its equivalent DN would then be cn=Robert Smith + uid=rsmith, ou=people,dc=example, dc=com (spaces or their absence between RDNs are not important).
The DN of the entry ou=people is ou=people,dc=example,dc=com. A DN describes the path to any entry in the DIT.
The entry dc=example, dc=com apparently has two RDNs (dc=example and dc=com). This is a common and legitimate construct (described further here) used for root (a.k.a. base or suffix) definitions. (If you were in a mood to be awkward about this stuff you could call it a multi-RDN RDN but let's not go there.)
To navigate the DIT we can define a path (a DN) to the place where our data is (cn=Robert Smith, ou=people,dc=example, dc=com will take us to a unique entry) or we can define a path (a DN) to where we think our data is (say, ou=people,dc=example,dc=com) then search for the attribute=value or multiple attribute=value pairs to find our target entry (or entries). If we want to write (modify in the LDAP jargon) the search will typically be to a unique entry, however, if we are interrogating the DIT it may be just unique'ish - we'll get everything that matches our search criteria.
The following diagram illustrates the DN and RDNs.
Further explanation with some worked examples.
2.5 LDAP Referrals and Replication
One of the more powerful aspects of LDAP (and X.500) is the inherent ability within the design to delegate the responsibility for maintenance of a part of the directory while continuing to see the directory as a consistent whole. Thus, a company directory may create a delegation (referral is the LDAP term) of the responsibility for a particular department's part of the overall directory to that department's LDAP server. In this respect LDAP almost exactly mirrors the DNS delegation concept for those familiar with the concept.
Unlike the DNS system, there is no option in the standards to tell the LDAP server to follow (resolve) a referral - it is left to the LDAP client to directly contact the new server using the returned referral. Equally, because the standard does not define LDAP data organisation it does not contravene the standard for an LDAP server to follow (resolve) the link and some LDAP servers perform this function automatically using a process that is usually called chaining.
OpenLDAP takes a literal view of the standard and does not chain by default it always returns a referral. However OpenLDAP can be configured to provide chaining by use of the overlay chain directive.
The built-in replication features of LDAP allows one or more copies of a directory (DIT) to be slaved from a single master (and even in some implementations between multiple masters) thus inherently creating a resilient structure.
It is important, however, to emphasize the difference between LDAP and a transactional database. When an update is performed on a master LDAP enabled directory, it may take some time (in computing terms) to update the slave(s) (or a peer master) - the master and slaves (or peer masters) may be unsynchronised for a period of time.
In the LDAP context, temporary lack of DIT synchronisation is regarded as unimportant. In the case of a transactional database, even a temporary lack of synchronisation is regarded as catastrophic. This emphasises the differences in the characteristics of data that should be maintained in an LDAP enabled directory versus a transactional database.
The configuration of Replication and Referral is discussed further and featured in the samples.
2.5.1 LDAP Referrals
Figure 2.5-1 below shows a search request with a base DN of dn:cn=thingie,o=widgets,dc=example,dc=com, to a referral based LDAP system, that is fully satisfied from the first LDAP server (LDAP1):
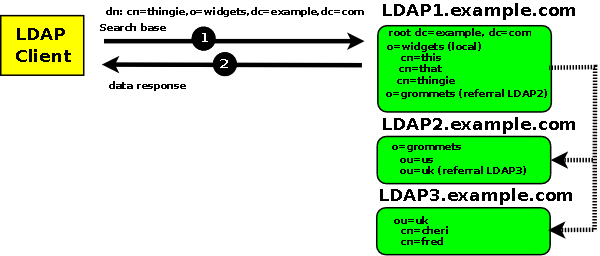
Figure 2.5-1 - Request satisfied from LDAP1 only
Figure 2.5-2 below shows a search request with a base DN of dn: cn=cheri,ou=uk,o=grommets,dc=example,dc=com, to a referral based LDAP system, that results in a series of referrals to the LDAP2 and LDAP3 servers, LDAP Clients always follow referrals:
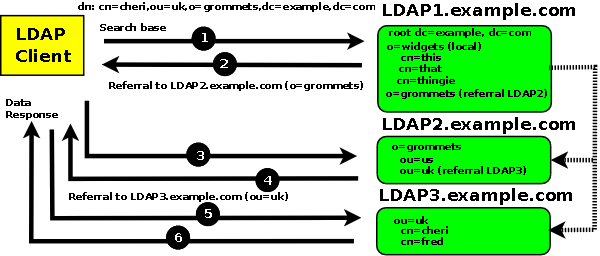
Figure 2.5-2 - Request generates referrals to LDAP2 and LDAP3
Notes:
- All client requests start at the global directory LDAP 1
- At LDAP 1, requests for any data with widgets as an RDN in the DN are satisfied immediately from LDAP1, for example:
dn: cn=thingie,o=widgets,dc=example,dc=com
- At LDAP 1 requests for any data with grommets as an RDN in the DN are referred to LDAP2, for example:
dn: cn=cheri,ou=uk,o=grommets,dc=example,dc=com
- At LDAP 2, requests for any data with uk as an RDN in the DN are referred to LDAP3, for example:
dn: cn=cheri,ou=uk,o=grommets,dc=example,dc=com
If the LDAP server is configured to chain (follow the referrals as shown by the alternate dotted lines) then a single data response will be supplied to the LDAP client. Chaining is controlled by LDAP server configuration and by values in the search request. Information on chaining.
The Figures illustrate explicit chaining using the referral ObjectClass, OpenLDAP servers may be configured to return a generic referral if the requested DN is not found during a search operation.
2.5.2 LDAP Replication
Replication features allow LDAP DIT updates to be copied to one or more LDAP systems for backup and/or performance reasons. In this context it is worth emphasizing that replication operates at the DIT level not the LDAP server level since there may be multiple DITs within an LDAP server. Replication occurs periodically within what is known as the replication cycle time (essentially the time taken to send the updated data to the replica and to receive acknowledgement of success). In general there are methods to reduce the replication cycle time by configuration but these will typically have a performance or network usage overhead. OpenLDAP, historically, used a separate daemon (slurpd) to perform replication but since version 2.3 the replication strategy has changed significantly with important gains in flexibility and configurable changes in the replication cycle time. There are two possible replication configurations and multiple variations on each configuration type.
Master-Slave: In a master-slave configuration a single DIT is updated (the Master or Provider in OpenLDAP jargon) and these updates are replicated or copied to one or more designated LDAP servers running slave DITs (a consumer in openLDAP jargon). The slave servers operate with read-only copies of the master DIT. Read-only users can operate quite happily with the servers containing the slave DITs but users who need to update the directory will need to access the server containing the master DIT. In certain conditions a Master-Slave configuration can provide significant load-balancing. However a Master-Slave configuration has two obvious shortcomings:
If all/most users have the ability/need to update the DIT then they will either have to access one server (with the slave DIT) for normal read access and another server (with the master DIT) to perform the update. Alternatively, they can always point to the server running the master DIT. In this latter case replication provides backup functionality only.
Since there is only one server containing a master DIT it represents a single point of failure for write operations (though the Slave DIT could be reconfigured to act as a Master in the event of a major failure).
Multi-Master: In a multi-master configuration one or more servers running master DITs may be updated and the resulting updates are propagated to the peer masters.
Historically, OpenLDAP did not support multi-master operation for quite some time but version 2.4 finally introduced multi-master capabilities. In this context, it may be worth pointing out two specific variations of the generic update-contention problem identified by the OpenLDAP project that apply to multi-master configurations and which are true for all LDAP systems:
Value-contention If two attribute updates are performed at the same time (within the replication cycle time) with different values, then, depending on the attribute type (SINGLE or MULTI-VALUED) the resulting entry may be in an incorrect or unusable state.
Delete-contention If one user adds a child entry at the same time (within the replication cycle time) as another user deletes the original entry, then the deleted entry will re-appear.
Figure 2.5-3 shows a number of possible replication configurations and combines them with referrals from the previous section to show the power and flexibility of LDAP. It need hardly be said that the majority of LDAP configurations are not quite as complicated.
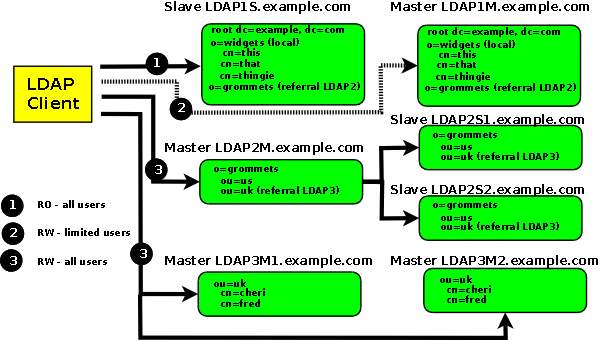
Figure 2.5-3 - Replication Configurations
Notes:
RO = Read-only, RW = Read-Write.
LDAP1 Client facing system is a Slave and is read only. Clients must issue modify operations (writes) to the Master.
LDAP2 Client facing system is a Master and it is replicated to two slaves.
LDAP3 is a Multi-Master and clients may issue reads (searches) and/or writes (modifies) to either system. Each master in this configuration could, in turn, have one or more slave DITs.
Chapter 3 - LDAP Schemas, objectsClasses and Attributes
Problems, comments, suggestions, corrections (including broken links) or something to add? Please take the time from a busy life to 'mail us' (at top of screen), the webmaster (below) or info-support at zytrax. You will have a warm inner glow for the rest of the day.