Name Authority Pointer (NAPTR) RR
The NAPTR RR is part of the Dynamic Delegation Discovery System (DDDS) defined in RFC 3401, RFC 3402, RFC 3403, RFC 3404 and RFC 3405. Doubtless there may have been a good reason for the title Dynamic Delegation Discovery System (DDDS) at one point in time and space or at least in 2002 when the RFCs were published. At this distance it simply looks like a someone wanted to invent a mnemonic.
Sadly the title obscures a powerful set of rules, of which the NAPTR RR is but one part, whereby an application can take some data (an Application User String or AUS), apply a Well Known First Rule to the AUS (transform the data), then use the transformed data to read from a database (in most cases this is an NAPTR RR from the DNS). The NAPTR RRs are then processed by the application, based on the defined Priority and Order sequence, the value of the flags and service parameters, to generate an FQDN (Fully Qualified Domain Name) or, using the algorithm contained in the NAPTR (a sed-like regular expression), a URI of some sort. If that sounds complicated it's because expressed in the general purpose language of the RFCs it is pretty complicated. The key point about the DDDS system is that is defines a general purpose method for either finding an FQDN (either an SRV RR or an A RR/AAAA RR) or re-directing to a URI. The NAPTR is a small (but extremely important) part of DDDS and its functionality can only be truly understood when read in conjunction with the detailed specification of an application which uses DDDS such as ENUM (defined by RFC 6116), SIP (RFC 3263), S-NAPTR (RFC 3958) or U-NAPTR (RFC 4848).
On first glance the NAPTR RR looks brutually complex. On second and third glances it remains so. Persevere, there is a end to the misery. The bright dawn of understanding will come. Only later than you had hoped.
- NAPTR Syntax
- NAPTR Use in DNS Discovery (non-ENUM use)
- ENUM DDDS Application Overview
- NAPTR ENUM Use
- ENUM Examples
- NAPTR Regexp Tester
NAPTR Syntax
The generic NAPTR format is defined and the various fields explained. However, in order to make any sense of NAPTR (defined by RFC 3403) it needs to be explained in the context of an application. The sections that follow and the examples use the ENUM application, other applications have different rule-sets (but the DDDS principles remain the same) and the appropriate RFC should be consulted. Starting with the NAPTR RR generic format:
Format
# generic format
owner-name ttl class NAPTR order pref flag params regexp replace
# NAPTR example
2.1.2.1 IN NAPTR 10 100 "U" "E2U+sip" "!^\\+44111555(.+)$!sip:7\\1@sip.example.com!" .
Where owner-name, ttl and class have the same meaning as with other RR types:
order 16 bit unsigned value (range 0 to 65535) the lowest number having the highest order, thus an order of 10 is of more importance (has a higher order value) than an order of 50.
pref Pref(erence) is nominally used only when two NAPTR RRs with the same owner-name also have the same order value and is used to indicate the users preference (all other things being equal). 16 bit unsigned value (range 0 to 65535) lower values having a higher preference, thus a preference of 10 is higher (is more preferred) than a preference of 50. Since NAPTR RRs carry additional information, applications may ignore the user preference field in order to find a suitable protocol in the params field.
flag Defined in RFC 3404 Section 4.3. Each flag is a single character from the set A-Z and 0-9. Almost all current applications that use NAPTR/DDDS support only a single flag but the specs caution that future applications may use more than one flag. Flag is defined to be application specific, that is, each application may define a specific use of the flag or which flags are valid, but applications are not supposed to define an alternative meaning for the flag. The flag is enclosed in quotes (""). Currently defined values are:
U - a terminal condition - the result of the regexp is a valid URI
S - a terminal condition - the replace field contains the FQDN of an SRV RR.
A - a terminal condition - the replace field contains the FQDN of an A RR (or AAAA RR).
P - a non-terminal condition - the protocol/services part of the params field determines the application specific behavior and subsequent processing lies outside the definition of DDDS.
"" (empty string) - a non-terminal condition defined by the ENUM application (RFC 6166) to indicate that regexp is empty and the replace field contains the FQDN of another NAPTR RR.
params defines the application specific service parameters. The generic format (defined in RFC 3404 Section 4.4) is:
protocol+rs
Where:
protocol defines the protocol used by the DDDS application. Protocol is a little misleading since it typically defines the service to be supported, such as E2U (E.164 to URI).
rs is the resolution service. There may be 0 or more resolution services each separated by +. ENUM further defines this to be a type field and allows a subtype separated by a colon (:). See ENUM.
While the DDDS specification defines a nominal format for this field almost every application uses some variant form.
regexp Defined in RFC 3402 Section 3.2 and enclosed in quotes (""). This field defines a sed-style (sed is a unix utility) substitution expression which is applied to the AUS. This expression takes the following format:
delimit ere delimit substitution delimit flag
Where:
delimit defines any suitable delimiting character. The same delimit character must be used in all three delimit fields in the regexp field. The delimiting character should be chosen to ensure it does not appear within the ere or substitution fields otherwise it will have to be escaped (leading to excessively gruesome strings). Most examples show the use of the ! character for this purpose since it is not valid in an E.164 number or a URI whereas the common sed delimiter character (/) appears in many styles of URI.
ere an extended regular expression as defined in IEEE POSIX 1003.2 (Section 2.8). This expression is applied to the AUS and the interim results are then applied to the substitution expression to create a final result. There is a regular expression tutorial here - including sed examples for the regular-expression-challenged reader (and aren't most of us).
substitution the interim results from the ere expression are applied to this expression to create a final result string. This expression can simply replace (ignore) the AUS (which happens frequently in ENUM) or using back references (of the form \1 through \9 and described in this tutorial) to manipulate or transform the AUS.
flag an optional flag which, if present, must be "i" and indicates that a case insensitive ere will be performed.
Note: The complete regexp appears inside a quoted string ("") in the DNS NAPTR RR. When used within a quoted string the \ (used as an escape character within the ere and substitution expressions) must be escaped by an additional \ (RFC 1464)). When sent on-the-wire the extra \ is removed resulting in valid ere and substitution expressions. Thus, if the NAPTR RR contains "!(\\+441115551234)!tel:\\1!" (invalid ere and substitution expressions) it will be sent on-the-wire as !(\+441115551234)!tel:\1! (valid ere and substitution expressions).
regexp Examples
In all cases the strings shown are as they would appear in the NAPTR RR - see note about escaping DNS backslash.
# all examples use ! as the delimiter for consistency
# and simplicity
# AUS = +441115551234 in all cases
!(\\+441115551234)!tel:\\1!
# explicit check of all characters in string
# the +441115551234 because of () creates a group
# which is referenced by \1 in substitution
# result = tel:+441115551234
!^(\\+441115551234)$!tel:\\1!
# this is functionally identical to the expression
# above but uses ^ and $ to anchor both ends of
# the expression, there is no technical reason to do this
# within an ere and the RFCs are silent on the topic
# result = tel:+441115551234
!(.+)!tel:\\1!
# given the AUS of +441115551234
# the expression (.+) sets back ref 1 = +441115551234
# . = any character, + = 0 or more times
# result = tel:+441115551212
!\\+44111(.+)!sip:775\\1@some.example.com!
# given the AUS of +441115551234 provides partial replacement
# removes the 44111 part and substitutes 775
# result = sip:7755551234@some.example.com
!.*!sip:jim@sip.example.com!
# reads and ignores AUS using .*
# and is called a simple replacement expression
# result = sip:james@sip.example.com
replace The replace string if not present must be indicated by a single dot (.). It is an error to have both a replace field and a regexp field, if replace is present then regexp should be an empty string (""). If present the replace field is assumed to be a valid FQDN (Fully Qualified domain Name which must always end with a dot) which may be used as a NAPTR RR lookup (ENUM application with flag = "" (empty)) or for S-NAPTR, SIP or U-NAPTR applications an SRV RR lookup (flag = "S") or an A/AAAA RR lookup (flag="A").
NAPTR Use in DNS Discovery
Many of the uses of DDDS (and the NAPTR RR) are related to discovery of the location of a server which supports a specific service type. This use is similar to that of the SRV RR but the sense of NAPTR allows for greater user control over the granularity of services provided. The following notes identify some of the key characteristics of such services:
SIP (RFC 3263) recommends that when initiating contact an initial lookup for an NAPTR RR is performed at the base domain name. Thus, if trying to resolve sip:me@some.example.com then an NAPTR lookup is done with the domain name some.example.com. Only if this fails should an SRV lookup be performed. The sense here is that NAPTR allows the user to define the preferred types of service to be used in the NAPTR RRs whereas the SRV RR provides operational details such as port number or server name. Because it is a discovery method is does not use the regexp field. The SIP NAPTR RR uses the replace field with the "S" flag resulting in an SRV lookup. SIP NAPTR examples (from the RFC):
NAPTR 50 50 "s" "SIPS+D2T" "" _sips._tcp.example.com.
NAPTR 90 50 "s" "SIP+D2T" "" _sip._tcp.example.com
NAPTR 100 50 "s" "SIP+D2U" "" _sip._udp.example.com.
The params field follows the protocol+rs format of the DDDS specification. IANA maintains a list of protocol types used by SIP.
S-NAPTR (RFC 3263) defines Straightforward NAPTR in which any service type can be discovered using NAPTR RRs. Because it is a discovery method is does not use the regexp field. S-NAPTR applications use the empty flag ("") to indicate the replace field contains the domain name of a further NAPTR RR (like ENUM). The flags "S" and "A" (the only other ones supported) respectively indicate the replace field contains names used for lookups of SRV or A/AAAA RRs. Some examples from the RFC:
NAPTR 100 10 "" "WP:whois++" ( ; service
"" ; regexp
bunyip.example. ; replace (NAPTR lookup)
)
NAPTR 100 20 "s" "WP:ldap" ( ; service
"" ; regexp
_ldap._tcp.myldap.example.com. ; replace (SRV lookup)
The params field uses a variation of the protocol+rs formula of the DDDS specification. IANA maintains a list of applications which are registered to use S-NAPTR.
U-NAPTR (RFC 4848) defines the same methods as those for S-NAPTR (using "", "S" and "A" flags and the replace field) but additionally provides support for the "U" flag for creating URIs and thus uses the regexp BUT limits registered applications using the feature to use only the substitution form of regexp thus meaning that ere processing is not required. U-NAPTR supported regexp fields must be of the form (from the RFC):
"!.*!<URI>!"
# the .* (any character 1 or more times)
# is fixed by the RFC and essentially ignores
# the AUS data. The result will always be URI
ENUM DDDS Application Overview
The DDDS system assumes that an application (or agent) captures or otherwise obtains a string of data by some automagical process. In the case of ENUM (RFC 6116) this string is assumed to be a telephone number in E.164 format (the full +country code, area code, NXX code, exchange number, for example, +1-212-555-1212 or +44-288-555-1212). The application creates an Application User String (AUS) which, in the case of ENUM, strips out any non-numeric characters, thus if the captured number was +44-111-555-1234 the AUS becomes +441115551234. The AUS is then transformed by the First Well Known Rule of the ENUM application into a domain name by removing the plus sign, reversing the digits, separating then with a dot and appending the name .e164.arpa (see reverse numbering for similar techniques being applied to IP addresses). The AUS transform looks like this:
AUS = +441115551234
# remove +
441115551234
# reverse digits
432155511144
# separate with a dot
4.3.2.1.5.5.5.1.1.1.4.4
# append .e164.arpa.
4.3.2.1.5.5.5.1.1.1.4.4.e164.arpa
Note: The AUS remains unchanged and is used in subsequent processing.
The resulting domain name (4.3.2.1.5.5.5.1.1.1.4.4.e164.arpa) is then used in a DNS query for one or more NAPTR RR(s). The NAPTR RR(s) are then processed to find a URI. This process is shown diagrammatically in figure 1 below (while the diagram is specific to ENUM the flow is essentially the same for any application which uses DDDS):
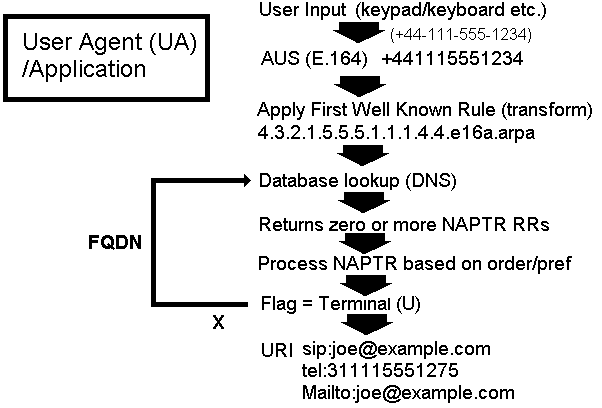
Figure 1 - ENUM Application Processing
NAPTR ENUM Use
The ENUM application defines the following application specific rules:
The Application User String (AUS) must begin with +.
flag only the U and "" empty flag are used. The U flag indicates the results of the regexp will be a URI suitable for the protocol defined in params (the replace field is ignored and must be a dot(.)). If the flag is "" (empty) then the replace field must contain an FQDN (and the regexp field must be an empty string ("")) which will be used to obtain further NAPTR RR(s) from the DNS.
params uses a serious variant of the DDDS standard params definition. This field must start with the value E2U (E.164 to URI). The generic form of this field used by ENUM is:
E2U+enumservice[+enumservice]
enumservice = type[:subtype]
The type and subtype fields are defined in the list maintained by IANA Enumservice Registrations Examples of valid definitions from this list are:
E2U+pres
E2U+voice:tel+sms:tel (compound form)
E2U+web:http
E2U+sms:mailto
E2U+sms:tel
E2U+sip
E2U+pstn
E2U+tel
In addition ENUM allows a type definition to begin with X- to indicate an experimental service (example X-TSIP could indicate an experimental SIP service extension under test), or P- to indicate a private ENUM service (for example P-mms could indicate a private multi-media service). Types that begin P- are intended to have private scope, that is they should only be used within a private network and should never appear in NAPTR RRs which are visible on the public (global) internet.
RFC 4725 defines the method of delegation of the E.164.arpa tree.
ENUM Examples
Example 1
; zone file fragment for 5.5.5.1.1.1.4.4.E164.ARPA
; user calls +44-111-555-1212 AUS = +441115551212
$TTL 2d ; zone TTL default = 2 days or 172800 seconds
$ORIGIN 5.5.5.1.1.1.4.4.E164.ARPA.
....
2.1.2.1 NAPTR (
10 ;order
100 ; preference
"U" ; terminal flag
"E2U+sip" ;sp
"!^\\+44111555(.+)$!sip:7\\1@sip.example.com!" ;ere
.) ; replace
NAPTR 10 101 "u" "E2U+pres" "!^.*$!mailto:sheila@example.com!" .
# first NAPTR result = sip:71212@sip.example.com
# second NAPTR ( typically used only if 1 fails)
# result = mailto:sheila@example.com
Note: The DNS requires \ escaping when used inside quoted strings as shown in the example. Note also the multi-line format used in the first NAPTR RR to allow comments against individual fields, the second NAPTR uses the single line format. Both are permitted by DNS and may be freely mixed in a zone file.
Example 2
; zone file fragment for 5.5.5.1.1.1.4.4.E164.ARPA
; compound example
; user calls +44-111-555-1212 AUS = +441115551212
$TTL 2d ; zone TTL default = 2 days or 172800 seconds
$ORIGIN 5.5.5.1.1.1.4.4.E164.ARPA.
....
2.1.2.1 NAPTR (
10 ;order
100 ; preference
"U" ; terminal flag
"E2U+voice:tel+sms:tel" ;sp
"!^(.+)$!tel:\\1!" ;ere
.) ; replace
NAPTR 10 101 "u" "E2U+sms" "!^.*$!mailto:sheila@example.com!" .
# first NAPTR result = tel:+441115551212
# and may be used for a call (voice) or sms
# this NAPTR regexp could have been written
# "!^(+441115551212)$!tel:\\1!"
# second NAPTR ( typically used only if 1 fails)
# result = mailto:sheila@example.com
NAPTR Regexp Tester
This NAPTR tester uses your browser's regular expression Javascript function (use View Source in your browser for the Javascript source code). It provides the functionality of the sed-like features of the NAPTR regexp field. Unlike the NAPTR it shows the intermediate results after the ere phase of the regexp as well as the final substitution phase. This may be useful for debugging expressions. While it has a number of ENUM specific features it may be used for any DDDS applications that use the regexp field of the NAPTR RR (not all do) by simply entering the AUS directly as described below.
If you are using the tester for ENUM enter or copy/paste the calling string in full E.164 format starting with + and including -, space or dot separators as required (all separators must be the same character) in the box labeled Call String:. The AUS is produced from this entry and placed in the AUS: box and the calculated domain name for the AUS is placed in the Query: box. By leaving Call String: blank and entering the AUS-under-test directly in the AUS: box ENUM AUS production is bypassed (and Query is set to empty). The rest of the tester is DDDS application agnostic. The regexp field without the enclosing "" should be entered or copy/pasted in the box labeled Regexp:. This field should be as it appears in the operational NAPTR RR including escaped \ characters.
Click the Test button and interim (post ere) results will appear in the box labeled I-Results: the first line begins with Ere and shows the ere expression used (minus all DNS \ escape characters). The final substitution result will appear in the Final: box the first line of which begins with Sub: and shows the extracted substitution expression used (minus all DNS \ escape characters). If you are very lucky the results may even be what you expect. Errors will appear in the Final: box with some, hopefully, useful diagnostics. All matches are displayed separately showing the found text and its character position in the string. If the "i" flag is present in the regexp then a case insensitive ere will be performed thus [AZ] will find the "a" in "cat", whereas without the "i" flag [aZ] would be required to find the "a" in "cat". Clear will zap all the fields - including the regexp that you just took 6 hours to develop. Use with care. See the notes below for limitations, support and capabilities.
Notes:
If the regular expression is invalid or syntactically incorrect the tester will display in the Final: box exactly what your browser thought of your attempt - sometimes it might even be useful.
The I-Results field shows (assuming your syntax is valid) the value of any backreference variables (in the range \1 - \9). If none exist (there were no subexpressions or groups in the regular expression) then, surprisingly, none will be displayed.
There is a regular expression tutorial here and if you want to mess around with a simple regex tester (without all the NAPTR stuff ) there is one here.
Notes:
Javascript implementations may vary from browser to browser. This feature was tested with MSIE 10, Gecko (Firefox 25.0.1), Opera 11.10 and Chrome (31.0.1650.57 m) - so will likely work with any WebKit based browser, which obviously includes Safari (and now even Opera!)). If the tester does not work for you we are very, very sad - but yell at your browser supplier not us. However, if you do think you have found an error please take the time to email using the link at the foot of this page.
If you get the message Match(es) = zero length in the results field this implies your browser's Javascript engine has choked on executing the ere expression. It has returned a valid match (there may be others in the string) but has (incorrectly) returned a length of 0 for the number of characters in the match. This appears to happen (Moz/FF and IE tested) when searching for a single character in a string when using the meta characters ? and *. For example, the regular expression e? on any string will generate the error (this expression will yield a match on every character in the string and is probably not what the user wanted).
Problems, comments, suggestions, corrections (including broken links) or something to add? Please take the time from a busy life to 'mail us' (at top of screen), the webmaster (below) or info-support at zytrax. You will have a warm inner glow for the rest of the day.