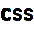2. DNS Concepts
If you already understand what DNS is and does and how it fits into the greater scheme of things - skip this chapter.
- 2.1 A brief History of Name Servers
- 2.2 DNS Concepts & Implementation
- 2.2.1 DNS Overview
- 2.2.2 Domains and Delegation
- 2.2.3 DNS Organization and Structure
- 2.2.4 DNS System Components
- 2.2.5 Zones and Zone Files
- 2.2.6 DNS Queries
- 2.2.6.1 Recursive Queries
- 2.2.6.2 Iterative Queries
- 2.2.6.3 Inverse Queries
- 2.2.7 Zone Updates
- 2.2.7.1 Full Zone Transfer (AXFR)
- 2.2.7.2 Incremental Zone Transfer (IXFR)
- 2.2.7.3 Notify (NOTIFY)
- 2.2.7.4 Dynamic Zone Updates
- 2.2.7.5 Alternative Dynamic DNS Approaches
- 2.3 DNS Security Overview
- 2.3.1 Security Threats
- 2.3.2 Security Types
- 2.3.3 Local Security
- 2.3.4 Server-Server (TSIG Transactions)
- 2.3.5 Server-Client (DNSSEC)
2.1 A brief History of Name Servers
.. or why do we have DNS servers
Without a Name Service there would simply not be a viable Internet. To understand why, we need to look at what DNS does and how and why it evolved.
A DNS translates (or maps) the name of a resource to its physical IP address - typically referred to as forward mapping
A DNS can also translate the physical IP address to the name of a resource - typically called reverse mapping.
Big deal.
Remember that the Internet (or any network for that matter) works by allocating every point (host, server, router, interface etc.) a physical IP address (which may be locally unique or globally unique).
Separation of Church and State.....
Without DNS every host (PC) which wanted to access a resource on the network (Internet), say a simple web page, for example, www.thing.com, would need to know its physical IP address. With 100 of millions of hosts and billions of web pages it is an impossible task - it's also pretty daunting even with just a handful of hosts and resources.
To solve this problem the concept of Name Servers was created in the mid 70's to enable certain attributes (properties) of a named resource to be maintained in a known location - the Name Server.
With a Name Server present in the network any host only needs to know the physical address of a Name Server and the name of the resource it wishes to access. Using this data it can find the address (or any other stored attribute or property) of the resource by interrogating (querying) the Name Server. Resources can be added, moved, changed or deleted at a single location - the Name Server. At a stroke network management was simplified and made more dynamic.
If it's broke....
We now have a new problem with our newly created Name Server concept. If our Name Server is not working our host cannot access any resource on the network. We have made the Name Server a critical resource. So we had better have more than one Name Server in case of failure.
To fix this problem the concept of Primary and Secondary Name Servers (many systems allow tertiary or more Name Servers) was born. If the Primary Name Server does not respond a host can use the Secondary (or tertiary etc.).
Man, we got more names than Webster....
As our network grows we start to build up a serious number of Names in our Name Server (database). This gives rise to three new problems.
Finding any entry in the database of names becomes increasingly slow as we power through many millions of names looking for the one we want. We need a way to index or organize the names.
If every host is accessing our Name Servers the load becomes very high. Maybe we need a way to spread the load across a number of servers.
With many Name (resource) records in our database the management problem becomes increasingly difficult as everyone tries to update all the records at the same time. Maybe we need a way to separate (or delegate) the administration of these Name (resource) records.
Which leads us nicely into the characteristics of the Internet's Domain Name System (DNS).

2.2 DNS Concepts & Implementation
The Internet's Domain Name System (DNS) is just a specific implementation of the Name Server concept optimized for the prevailing conditions on the Internet.
2.2.1 DNS Overview
From our brief history of Name Servers we saw how three needs emerged:
- The need for a hierarchy of names
The need to spread the operational loads on our name servers
- The need to delegate the administration of our Name servers
The Internet Domain Name System elegantly solves all these problems at the single stroke of a pen (well actually the whole of RFC 1034 to be precise).
2.2.2 Domains and Delegation
The Domain Name System uses a tree (or hierarchical) name structure. At the top of the tree is the root
followed by the Top Level Domains (TLDs) then the domain-name and any number of lower levels each separated with a dot.
NOTE: The root of the tree is represented most of the time as a silent dot ('.') but there are times as we shall see later when it very important.
Top Level Domains (TLDs) were split into two types:
Generic Top Level Domains (gTLD), for example, .com, .edu, .net, .org, .mil etc.
Country Code Top Level Domain (ccTLD), for example .us, .ca, .tv , .uk etc.
Note: Country Code TLDs (ccTLDs) use a standard two letter sequence defined by ISO 3166.
In 2004 a sub-category of the gTLDs known as sTLDs (Sponsored TLDs) which implies they may have limited registration was created. Examples of early sTLDs included .aero, .museum, .travel, and .jobs. The historic gTLDs offered a loose categorization of users who could register under the gTLD but in practice many had open registration requirements but this notably excluded .mil, .edu, .gov and .int all of which has (and still have) limited registration.
Finally, since 2011 the TLD policy is essentially unrestricted, if you pay enough money and adopt the operating procedures laid down anyone can register a sponsored TLD. Look forward to a whole set of new TLDs like .singles, .kitchen and .construction arriving.
Figure 1-1 shows this diagrammatically.
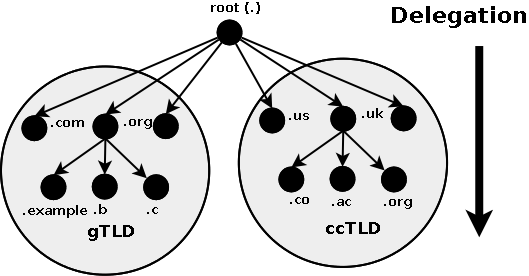
Figure 1-1 Domain Structure and Delegation
What is commonly called a Domain Name is actually a combination of a domain-name and a TLD and is written from LEFT to RIGHT with the lowest level in the hierarchy on the left and the highest level on the right.
domain-name.tld # example.com
In the case of the gTLDs, such as .com, .net etc., the user part of the delegated name - the name the user registered - is a Second Level Domain (SLD). It is the second level in the hierarchy. The user part is therefore frequently simply referred to as the SLD. So the the Domain Name in the example above can be re-defined to consist of:
sld.tld # example.com
The term Second Level Domain (SLD) is much less useful with ccTLDs where the user registered part is typically the Third Level Domain, for example:
example.co.uk
example.com.br
The term Second Level Domain (SLD) provides technical precision but can be confusing when applied to a generic concept like a user domain - unless the precision is required we will continue to use the generic term Domain Name or simply Domain to describe the whole name, for instance, what this guide calls a Domain Name would be example.com or example.co.uk.
Authority and Delegation
The concepts of Delegation and Authority lie at the core of the domain name system hierarchy. The Authority for the root domain lies with Internet Corporation for Assigned Numbers and Names (ICANN). Since 1998 ICANN, a non-profit organisation, has assumed this responsibility from the US government.
The gTLDs are authoritatively administered by ICANN and delegated to a series of accredited registrars. The ccTLDs are delegated to the individual countries for administration purposes. Figure 1.0 above shows how any authority may in turn delegate to lower levels in the hierarchy, in other words it may delegate anything for which it is authoritative. Each layer in the hierarchy may delegate the authoritative control to the next lower level.
In the case of ccTLDs countries like Canada (ccTLD .ca) and the US (ccTLD .us) and others with federated governments decided that they would administer at the national level and delegate to each province (Canada) or state (US) a two character province/state code, for example, .qc = Quebec, .ny = New York, md = Maryland etc.. Thus mycompany.md.us would be the Domain Name of mycompany which was delegated from the state of MaryLand in the US. This was the delegation model until around 2006 when both countries changed their registration policies and adopted an essentially flat delegation model. Thus, today you can register mycompany.us or mycompany.ca (as long as they are available). The old delegation models are still valid and you still see domains such as quebec.qc.ca as well as numerous other examples of the multi-layer delegation model.
Countries with more centralized governments, like the UK, Brazil and Spain and others, opted for functional segmentation in their delegation models, for example, .co = company, .ac = academic etc.. Thus mycompany.co.uk is the Domain Name of mycompany registered as a company from the UK registration authority.
Delegation within any domain may be almost limitless and is decided by the delegated authority, for example, the US and Canada both delegated city within province/state domains thus the address (or URL) tennisshoes.ne.us is the town of Tennis Shoes in the State of Nebraska in the United States and we could even have mycompany.tennisshoes.ne.us.
By reading a domain name from RIGHT to LEFT you can track its delegation. This unit of delegation can also be referred to as a zone in standards documentation.
So What is www.example.com
From our reading above we can see that www.example.com is built up from www and example.com. The Domain-Name example.com part was delegated from a gTLD registrar which in turn was delegated from ICANN.
The www part was chosen by the owner of the domain since they are now the delegated authority for the example.com name. They own EVERYTHING to the LEFT of the delegated Domain Name.
The leftmost part, www in this case, is called a host name. By convention (but only convention) web sites have the 'host' name of www (for world wide web) but you can have a web site whose name is fred.example.com - no-one may think of typing this into their browser but that does not stop you doing it! Equally you may have a web site whose access address (URL) is www.example.com running on a server whose real name is mary.example.com. Again this is perfectly permissable. In short the host part may refer to a real host name or a service name such as www. Since the domain owner controls this process it's all allowed.
Every computer, or service, that is addressable (has a URL) via the Internet or an internal network has a host name part, here are some more illustrative examples:
www.example.com - the company web service
ftp.example.com - the company file transfer protocol server
pc17.example.com - a normal PC or host
accounting.example.com - an accounting system
A host name part must be unique within the Domain Name but can be anything the owner of example.com wants.
Finally lets look at this name:
www.us.example.com
From our previous reading we figure its Domain Name is example.com, www probably indicates a web site, which leaves the us part.
The us part was allocated by the owner of example.com (they are authoritative) and is called a sub-domain. In this case the delegated authority for example.com has decided that their company organization is best served by a country based sub-domain structure. They could have delegated the responsibility internally to the US subsidiary for administration of this sub-domain, which may in turn have created a plant based structure, such as, www.cleveland.us.example.com which could indicate the web site of the Cleveland plant in the US organisation of example.com.
To summarise the OWNER can delegate, IN ANY WAY THEY WANT, ANYTHING to the LEFT of the Domain Name they own (were delegated). The owner is also RESPONSIBLE for administering this delegation which means running, or delegating the task of running, a DNS containing Authoritative information (or records) for their Domain Name (or zone).
Note: Names such as www.example.com and www.us.example.com are commonly - but erroneously - referred to as Fully Qualified Domain Names (FQDN). Technically an FQDN unambiguously defines a name from any starting point to the root and as such must contain the normally silent dot at the end. To illustrate "www.example.com." is an FQDN "www.example.com" is not.
2.2.3 DNS Organization and Structure
The Internet's DNS exactly maps the 'Domain Name' delegation structure described above. There is a DNS server running at each level in the delegated hierarchy and the responsibility for running the DNS lies with the AUTHORITATIVE control at that level.
Figure 1-2 shows this diagrammatically.
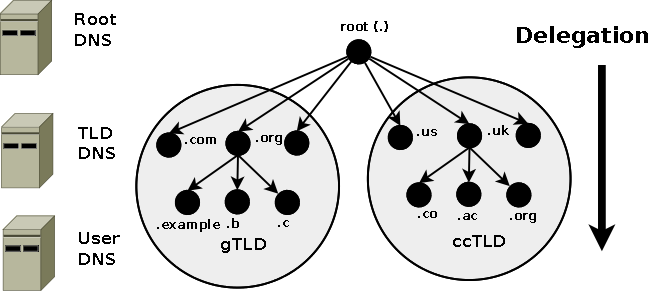
Figure 1-2 DNS mapped to Domain Delegation
The Root Servers (Root DNS) are the responsibility of ICANN but operated by a consortium under a delegation agreement. ICANN created the Root Servers Systems Advisory Committee (RSSAC) to provide advice and guidance as to the operation and development of this critical resource. The IETF was requested by the RSSAC to develop the engineering standards for operation of the Root-Servers. This request resulted in the publication of RFC 2870.
There are currently (mid 2003) 13 root-servers world-wide. The Root-Servers are known to every public DNS server in the world and are the starting point for every name lookup operation (or query). To create additional resilience each root-server typically has multiple instances (copies) spread throughout the world. Each instance has the same IP address but data is sent to the closest instance using a process called anycasting.
The TLD servers (ccTLD and gTLD) are operated by a variety of agencies and organizations (under a fairly complex set of agreements) called Registry Operators.
The Authority and therefore the responsibility for the User (or Domain Name) DNS servers lies with the owner of the domain. In many cases this responsibility is delegated by the owner of the Domain to an ISP, Web Hosting company or increasingly a registrar. Many companies, however, elect to run their own DNS servers and even delegate the Authority and responsibility for sub-domain DNS servers to separate parts of their organization.
When any DNS cannot answer (resolve) a request (a query) for a domain name from a client, for instance, example.com, the query is passed to a root-server which will direct (refer) the query to the appropriate TLD DNS server (for .com) which will in turn direct (refer) it to the appropriate Domain (User) DNS server.
2.2.4 DNS System Components
A Domain Name System (DNS) as defined by RFC 1034 includes three parts:
- Data which describes the domain(s)
- One or more Name Server programs.
- A resolver program or library.
A single DNS server may support many domains. The data for each domain describes global properties of the domain and its hosts (or services). This data is defined in the form of textual Resource Records organized in Zone Files. The format of Zone files is defined in RFC 1035 and is supported by most DNS software.
The Name Server program typically does three things:
- It will read a configuration file which defines the zones for which it is responsible.
- Depending on the Name Servers functionality a configuration file may describe various behaviours, for instance, to cache or not. Some DNS servers are very specialized and do not provide this level of control.
- Respond to questions (queries) from local or remote hosts.
The resolver program or library is located on each host and provides a means of translating a users request for, say, www.thing.com into one or more queries to DNS servers using UDP (or TCP) protocols.
Note: The resolver on all Windows systems and the majority of *nix systems is actually a stub resolver - a minimal resolver that can only work with a DNS that supports recursive queries. The caching resolver on MS Windows 2K and XP is a stub resolver with a cache to speed up responses and reduce network usage.
While BIND is the best known of the DNS servers and much of this guide documents BIND features, it is by no means the only solution or for that matter the only Open Source solution. Appendix C: lists many alternate solutions. The zone file formats which constitute the majority of the work (depending on how many sites you operate) is standard (defined by RFC 1035) and is typically supported by all DNS suppliers. Where a feature is unique to BIND we indicate it clearly in the text so you can keep your options open!
2.2.5 Zones and Zone Files
Zone files contain Resource Records that describe a domain or sub-domain. The format of zone files is an IETF standard defined by RFC 1035. Almost any sensible DNS software should be able to read zone files. A zone file will consist of the following types of data:
- Data that indicates the top of the zone and some of its general properties (a SOA Record).
- Authoritative data for all nodes or hosts within the zone (typically A (IPv4) or AAAA (IPv6) Records).
- Data that describes global information for the zone (including mail MX Records and Name Server NS Records).
- In the case of sub-domain delegation the name servers responsible for this sub-domain (one or more NS Records).
- In the case of sub-domain delegation one or more glue records that allows a name server to reach the sub-domain (typically one or more A or AAAA Records) for the sub-domain name servers.
The individual Resource Records are described and numerous sample configuration files are provided and documented.
2.2.6 DNS Queries
The major task carried out by a DNS server is to respond to queries (questions) from a local or remote resolver or other DNS acting on behalf of a resolver. A query would be something like 'what is the IP address of fred.example.com'.
A DNS server may receive such a query for any domain. DNS servers may be configured to be authoritative for some domains, slaves for others, forward queries or other combinations.
Most of the queries that a DNS server will receive will be for domains for which it has no knowledge, that is, for which it has no local zone files. DNS software typically allows the name server to respond in different ways to queries about which it has no knowledge.
There are three types of queries defined for DNS:
A recursive query - the complete answer to the question is always returned. DNS servers are not required to support recursive queries.
An Iterative (or non-recursive) query - where the complete answer MAY be returned or a referral provided to another DNS. All DNS servers must support Iterative queries.
An Inverse query - where the user wants to know the domain name given a resource record. Reverse queries were poorly supported, very infrequent and are now obsolete (RFC 3425).
Note: The process called Reverse Mapping (returns a host name given an IP address) does not use Inverse queries but instead uses Recursive and Iterative (non-recursive) queries using the special domain name IN-ADDR.ARPA.
Historically reverse IPv4 mapping was not mandatory. Many systems however now use reverse mapping for security and simple authentication schemes (especially mail servers) so proper implementation and maintenance is now practically essential. IPv6 originally mandated reverse mapping but, like a lot of the original IPv6 mandates, has now been rolled-back.
2.2.6.1 Recursive Queries
A recursive query is one where the DNS server will fully answer the query (or give an error). DNS servers are not required to support recursive queries and both the resolver (or another DNS acting recursively on behalf of another resolver) negotiate use of recursive service using a bit (RD) in the query header.
There are three possible responses to a recursive query:
- The answer to the query accompanied by any CNAME records (aliases) that may be useful. The response will indicate whether the data is authoritative or cached.
- An error indicating the domain or host does not exist (NXDOMAIN). This response may also contain CNAME records that pointed to the non-existing host.
- An temporary error indication - for instance, can't access other DNS's due to network error etc..
In a recursive query a DNS Resolver will, on behalf of the client (stub-resolver), chase the trail of DNS system across the universe to get the real answer to the question. The journey of a simple query such as 'what is the IP address of www.example.com' to a DNS Resolver which supports recursive queries but is not authoritative for example.com is shown in Diagram 1-3 below:
Diagram 1-3 Recursive Query Processing
The user types www.example.com into their browser address bar. The browser issues a standard function library call (1) to the local stub-resolver.
The stub-resolver sends a query (2) 'what is the IP address of www.example.com' to locally configured DNS resolver (aka recursive name server). This is a standard DNS query requesting recursive services (RD (Recursion Desired) = 1).
The DNS Resolver looks up the address of www.example.com in its local tables (its cache) and does not find it. (If it were found it would be returned immediately to the Stub-resolver in an answer message and the transaction would be complete.)
The DNS resolver sends a query (3) to a root-server (every DNS resolver is configured with a file that tells it the names and IP addresses of the root servers) for the IP of www.example.com. (Root-servers, TLD servers and correctly configured user name servers do not, a matter of policy, support recursive queries so the Resolver will, typically, not set Recursion Desired (RD = 0) - this query is, in fact, an Iterative query.)
The root-server knows nothing about example.com, let alone the www part, but it does know about the next level in the hierarchy, in this case, the .com part so it replies (answers) with a referral (3) pointing at the TLD servers for .com.
The DNS Resolver sends a new query (4) 'what is the IP address of www.example.com' to one of the .com TLD servers. Again it will use, typically, an Iterative query.
The TLD server knows about example.com, but knows nothing about www so, since it cannot supply a complete response to the query, it replies (4) with a referral to the name servers for example.com.
The DNS Resolver sends yet another query (5) 'what is the IP address www.example.com' to one of the name servers for example.com. Once again it will use, typically, an Iterative query.
The example.com zone file defines a A (IPv4 address) record so the authoritative server for example.com returns (5) the A record for www.example.com (it fully answers the question).
The DNS Resolver sends the response (answer) www.example.com=x.x.x.x to the client's stub-resolver (2) and then places this information in its cache.
The stub-resolver places the information www.example.com=x.x.x.x in its cache (since around 2003 most stub-resolvers have been caching stub-resolvers) and responds to the original standard library function call (1) with www.example.com = x.x.x.x.
The browser receives the response to its standard function call, places the information in its cache (really) and initiates an HTTP session to the address x.x.x.x. DNS transaction complete. Quite simple really, not much could possibly go wrong.
In summary, the stub-resolver demands recursive services from the DNS Resolver. The DNS Resolver provides a recursive service but uses, typically, Iterative queries to achieve it.
Note: The resolver on Windows and most *nix systems is a stub-resolver (in point of fact, in most modern systems it is a Caching stub-Resolver) - which is defined in the standards to be a minimal resolver which cannot follow referrals. If you reconfigure your local PC or Workstation to point to a DNS server that only supports Iterative queries - it will not work. Period.
2.2.6.2 Iterative (non-recursive) Queries
A Iterative (or non-recursive) query is one where the DNS server may provide an answer or a partial answer (a referral) to the query (or give an error). All DNS servers must support non-recursive (Iterative) queries. An Iterative query is technically simply a normal DNS query that does not request Recursive Services.
There are four possible responses to a non-recursive query:
- The answer to the query accompanied by any CNAME records (aliases) that may be useful (in a Iterative Query this will ONLY occur if the requested data is already available in the cache). The response will indicate whether the data is authoritative or cached.
- An error indicating the domain or host does not exist (NXDOMAIN). This response may also contain CNAME records that pointed to the non-existing host.
- An temporary error indication, for instance, can't access other DNS's due to network error etc..
- A referral: If the requested data is not available in the cache then the name and IP addess(es) of one or more name server(s) that are closer to the requested domain name (in all cases this is the next lower level in the DNS hierarchy) will be returned. This referral may, or may not be, to the authoritative name server for the target domain.
In Diagram 1-3 above the transactions (3), (4) and (5) are normally all Iterative queries. Even if the DNS server requested Recursion (RD=1) it would be denied and a normal referral (or answer) returned. Why use Iterative queries? They are much faster, the DNS server receiving the query either already has the answer in its cache, in which case it sends it, or not, in which case it sends a referral. No messing around. Iterative queries give the requestor greater control. A referral typically contains a list of name servers for the next level in the DNS hierarchy. The requestor may have additional information about one or more of these name servers in its cache (including which is the fastest) from which it can make a better decision about which name server to use. Iterative queries are also extremely useful in diagnostic situations.
2.2.6.3 Inverse Queries
Historically, an Inverse query mapped a resource record to a domain. An example Inverse query would be 'what is the domain name for this MX record'. Inverse query support was optional and it was permitted for the DNS server to return a response Not Implemented.
Inverse queries are NOT used to find a host name given an IP address. This process is called Reverse Mapping (Look-up) uses recursive and Iterative (non-recursive) queries with the special domain name IN-ADDR.ARPA.
Inverse queries went the way of all "seemed like a good idea at the time" concepts when they were finally obsoleted by RFC 3425.
2.2.7 Zone Updates
The initial design of DNS allowed for changes to be propagated using Zone Transfer (AXFR) but the world of the Internet was simpler and more sedate in those days (1987). The desire to speed up the process of zone update propagation while minimising resources used has resulted in a number of changes to this aspect of DNS design and implementation from simple - but effective - tinkering such as Incremental Zone Transfer (IXFR) and NOTIFY messages to the concept of Dynamic Updates which have significant security consequences if not properly implemented. Diagram 1-4 show zone transfer capabilities.
Warning: While zone transfers are generally essential for the operation of DNS systems they are also a source of threat. A A slave Name Server can become poisoned if it accepts zone updates from a malicious source. Care should be taken during configuration to ensure that, as a minimum, the 'slave' will only accept transfers from known sources. The example configurations provide these minimum precautions. Security Overview outlines some of the potential threats involved.
2.2.7.1 Full Zone Update (AXFR)
The original DNS specifications (RFC 1034 & RFC 1035) envisaged that Slave (or secondary) Name Servers would 'poll' the Domain (or zone) Master. The time between such 'polling' is determined by the refresh value on the domain's SOA Resource Record
The polling process is accomplished by the Slave sending a query to the Master requesting its current SOA resource record (RR). If the serial number of this RR is higher than the current one maintained by the Slave, a zone transfer (AXFR) is requested. This is why it is vital to be very disciplined about updating the SOA serial number every time anything changes in ANY of the zone records.
Zone transfers are always carried out using TCP on port 53 whereas normal DNS query operations use UDP on port 53.
2.2.7.2 Incremental Zone Update (IXFR)
Transferring very large zone files can take a long time and waste bandwidth and other resources. This is especially wasteful if only a single RR has been changed! RFC 1995 introduced Incremental Zone Transfers (IXFR) which as the name suggests allows the Slave and Master to transfer only those records that have changed.
The process works as for AXFR. The Slave sends a query for the domain's SOA RR every refresh interval. If the serial number of the SOA record is higher than the current one maintained by the Slave it requests a zone transfer and indicates whether or not it is capable of accepting an Incremental Transfer (IXFR). If both Master and slave support the feature an Incremental Transfer (IXFR) takes place otherwise a Full Transfer (AXFR) takes place. Incremental Zone transfers use TCP on port 53, whereas normal DNS queries operations use UDP on port 53.
The default mode for BIND when acting as a Slave is to request IXFR unless it is configured not to using the request-ixfr parameter in the server or options clause of the named.conf file.
The default mode for BIND when acting as a Master is to use IXFR only when the zone is dynamic. The use of IXFR is controlled using the provide-ixfr parameter in the server or options clause of the named.conf file.
2.2.7.3 Notify (NOTIFY)
RFC 1912 recommends a REFRESH interval of up to 12 hours on the REFRESH interval of an SOA Resource Record. This means that, in the worst case, changes to the Master Name Server may not be visible at the Slave Name Server(s) for up to 12 hours. In a dynamic environment this may be unacceptable.
RFC 1996 introduced a scheme whereby the Master will send a NOTIFY message to the Slave Name Server(s) that a change MAY have occurred in the domain records. The Slave(s) on receipt of the NOTIFY will request the latest SOA Resource Record and if the serial number of the SOA RR is greater than its current value it will initiate a zone transfer using either a Full Zone Transfer (AXFR) or an Incremental Zone Transfer (IXFR).
NOTIFY behaviour in BIND is controlled by notify, also-notify and notify-source parameters in the zone or options statements of the named.conf file.

Diagram 1-4 Master - Slave Interaction and Zone Transfer
Zone Transfer Process Description
The time taken to propagate zone changes throughout the Internet is determined by two major factors. First, the time taken to update all the Domain's Name servers when any zone change occurs. This, in turn, is determined by the method used to initiate zone transfers to all Slave Name Servers which may be passive (the Slave will periodically poll the Master) or Active (the Master will send a NOTIFY to its configured Slave(s)). Both methods are described below. Second, the current TTL value (prior to its change) on any changed zone record will determine when Resolvers will refresh their caches by interrogating the Authoritative Name Server.
If the Master has been configured to support NOTIFY messages then whenever the status of the Master's zone file (1) changes it will send a NOTIFY message (2) to each configured Slave. A NOTIFY message does not necessarily indicate that the zone file has changed, for example, if the Master or the zone is reloaded then a NOTIFY message is triggered even if no changes have occured. When the Slave receives a NOTIFY message it follows the procedure defined in Step 3 below.
Irrespective of whether the Master has been configured to support NOTIFY messages or not the Slave will always use the passive or 'polling' process described in this step. (While on its face this seem superflous in cases where the Master has been configured to use NOTIFY, however, it does provide protection again lost NOTIFY messages due to mal-configuration or malicious attack.) When a Slave server is loaded it will read any current saved zone file (see file statement) or immediately intitate a zone transfer if there is no saved zone file. It then starts a timer using the refresh value in the zone's SOA RR. When this timer expires the Slave follows the procedure defined in Step 3 below.
If the Slave's refresh timer expires OR it receives a NOTIFY message the Slave will immediately issue a query for the zone Master's SOA RR (3).
When the answer arrives (4) the Slave compares the serial number of its current SOA RR with that of the answer (the Master's SOA RR). If the value of the Master SOA RR serial number is greater than the current serial number in the Slave's SOA copy then a zone transfer (5) is intiated by the Slave. (The gruesome details of the serial number arithmetic is defined in RFC 1982 and clarified in RFC 2181, the date based convention used for serial numbers is defined here). If the slave fails to read the Master's SOA RR (or fails to intiate the zone transfer) then it will try again after the retry time defined in the zone's SOA RR but will continue answering Authoritatively for the Domain (or zone). The retry procedure will be repeated (every retry interval) either until it succeeds (in which case the process continues at step 5 below) or until the expiry timer of the zone's SOA RR is reached, at which point the Slave will stop answering queries for the Domain.
The Slave always intitiates (5) a zone transfer operation (using AXFR or IXFR) using TCP on Port 53 (this can be configured using the transfer-source statement).
The Master will transfer the requested zone file (6) to the slave. On completion the Slave will reset its refresh and expiry timers.
2.2.7.4 Dynamic Update
The classic method of updating Zone Resource Records is to manually edit the zone file and then stop and start the name server to propagate the changes. When the volume of changes reaches a certain level this can become operationally unacceptable - especially considering that in organisations which handle large numbers of Zone Files, such as service providers, BIND itself can take a long time to restart at it plows through very large numbers of zone statements.
The 'holy grail' of DNS is to provide a method of dynamically changing the DNS records while DNS continues to service requests.
There are two architectural approaches to solving this problem:
- Allow 'run-time' updating of the Zone Records from an external source/application.
- Directly feed the DNS from a database which can be dynamically updated. BIND provides two APIs to enable this, other DNS implemenations provide embedded database access.
RFC 2136 takes the first approach and defines a process where zone records can be updated from an external source. The key limitation in this specification is that a new domain cannot be added dynamically. All other records within an existing zone can be added, changed or deleted. This limitation is also true for both of BIND's APIs as well.
As part of RFC 2136 the term Primary Master was coined to describe the Name Server defined in the SOA Resource Record for the zone. The significance of this term is that when dynamically updating records it is essential to update only one server even though there may be multiple master servers for the zone. In order to solve this problem a 'boss' server must be selected, this 'boss' server (the Primary Master) has no special characteristics other than it is defined as the Name Server in the SOA record and may appear in an allow-update clause to control the update process.
DDNS is normally associated with Secure DNS features such as TSIG - RFC 2845 & TKEY - RFC 2930. Dynamic DNS (DDNS) does not REQUIRE TSIG/TKEY. However by enabling Dynamic DNS you are also opening up the possibility of master zone file corruption or poisoning. Simple IP address protection (acl) can be configured into BIND but this provides - at best - limited protection. For that reason, serious users of Dynamic DNS will always use TSIG/TKEY procedures to authenticate incoming update requests.
In BIND DDNS is defaulted to deny from all hosts. Control of Dynamic Update is provided by the BIND allow-update (usable with and without TSIG/TKEY) and update-policy (only usable with TSIG/TKEY) clauses in the zone or options statements of the named.conf file.
There are a number of Open Source tools which will initiate Dynamic DNS updates these include dnsupdate (not the same as DNSUpdate) and nsupdate which is distributed with bind-utils.
2.2.7.5 Alternative Dynamic DNS Approaches
As noted above the major limitation in the standard Dynamic DNS (RFC 2136) approach is that new domains cannot be created dynamically.
BIND-DLZ takes a much more radical approach and, using a serious patch to BIND, allows replacement of all zone files with a single zone file which defines a database entry. The database support, which includes most of the major databases (MySQL, PostgreSQL, BDB and LDAP among others) allows the addition of new domains as well as changes to pre-existing domains without the need to stop and start BIND. As with all things in life there is a trade-off and performance can drop precipitously. Current work being carried (early 2004) out with a High performance Berkeley DB (BDB) is showing excellent results approaching raw BIND performance.
PowerDNS an authoritative only name server takes a similar approach with its own (non-BIND) code base by referring all queries to the database back-end and thereby allow new domains to be added dynamically.
2.3 Security Overview
DNS Security is a huge and complex topic. It is made worse by the fact that almost all the documentation dives right in and you fail to see the forest for all the d@!#*d trees.
The critical point is to first understand what you want to secure - or rather what threat level you want to secure against. This will be very different if you run a root server rather than running a modest in-house DNS serving a couple of low volume web sites.
The term DNSSEC is thrown around as a blanket term in a lot of documentation. This is not correct. There are at least three types of DNS security, two of which are - relatively - painless and DNSSEC which is - relatively - painful.
Security is always an injudicious blend of real threat and paranoia - but remember just because you are naturally paranoid does not mean that they are not after you!
2.3.1 Security Threats
In order to be able to assess both the potential threats and the possible counter-measures it is first and foremost necessary to understand the normal data flows in a DNS system. Diagram 1-5 below shows this flow.
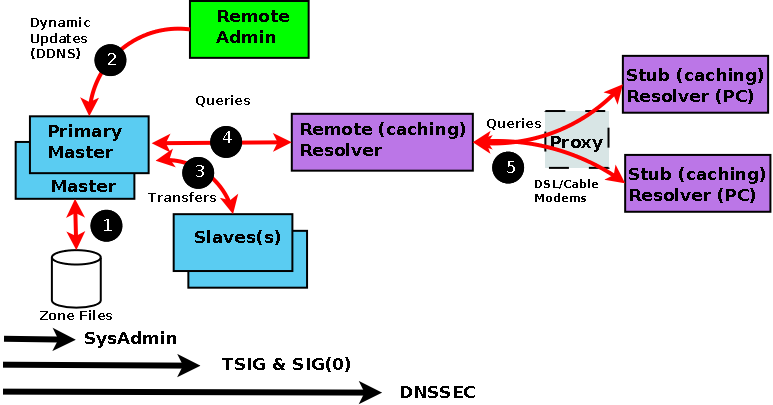
Diagram 1-5 DNS Data Flow
Every data flow (each RED line above) is a potential source of threat! Using the numbers from the above diagram here is what can happen at each flow - beware, you may not sleep soundly tonight:
| Number |
Area |
Threat |
| (1) |
Zone Files |
File Corruption (malicious or accidental). Local threat. |
| (2) |
Dynamic Updates |
Unauthorized Updates, IP address spoofing (impersonating update source). Server to Server (TSIG Transaction) threat. |
| (3) |
Zone Transfers |
IP address spoofing (impersonating update source). Server to Server (TSIG Transaction) threat. |
| (4) |
Remote Queries |
Cache Poisoning by IP spoofing, data interception, or a subverted Master or Slave. Server to Client (DNSSEC) threat. |
| (5) |
Resolver Queries |
Data interception, Poisoned Cache, subverted Master or Slave, local IP spoofing. Remote Client-client (DNSSEC) threat. |
The first phase of getting a handle on the problem is to figure (audit) what threats are applicable and how seriously do YOU rate them or do they even apply. As an example; if you don't do Dynamic Updates (BIND's default mode) - there is no Dynamic Update threat! Finally in this section a warning: the further you go from the Master the more complicated the solution and implementation. Unless there is a very good reason for not doing so, we would always recommend that you start from the Master and work out.
2.3.2 Security Types
We classify each threat type below. This classification simply allows us select appropriate remedies and strategies for avoiding or securing our system. The numbering used below relates to diagram 1-3.
(1) The primary source of Zone data is normally the Zone Files (and don't forget the named.conf file which contains lots of interesting data as well). This data should be secure and securely backed up. This threat is classified as Local and is typically handled by good system administration.
(2) The BIND default is to deny Dynamic Zone Updates. If you have enabled this service or require to it poses a serious threat to the integrity of your Zone files and should be protected. This is classified as a Server-Server (Transaction) threat.
(3) If you run slave servers you will do zone transfers. Note: You do NOT have to run with slave servers, you can run with multiple masters and eliminate the transfer threat entirely. This is classified as a Server-Server (Transaction) threat.
(4) The possibility of Remote Cache Poisoning due to IP spoofing, data interception and other hacks is a judgement call if you are running a simple web site. If the site is high profile, open to competitive threat or is a high revenue earner you have probably implemented solutions already. This is classified as a Server-Client threat.
(5) The current DNSSEC standards define a security aware resolver and this concept is under active development by an number of groups round the world. This is classified as a Server-Client threat.
2.3.3 Security - Local
Normal system administration practices such as ensuring that files (configuration and zone files) are securely backed-up, proper read and write permissions applied and sensible physical access control to servers may be sufficient.
Implementing a Stealth (or Split) DNS server provides a more serious solution depending on available resources.
Finally you can run BIND (named) in a chroot jail.
2.3.4 Server-Server (TSIG Transactions)
Zone transfers. If you have slave servers you will do zone transfers. BIND provides Access Control Lists (ACLs) which allow simple IP address protection. While IP based ACLs are relatively easy to subvert using IP addreess spoofing they are a lot better than nothing and require very little work. You can run with multiple masters (no slaves) and eliminate the threat entirely. You will have to manually synchronise zone file updates but this may be a simpler solution if changes are not frequent.
Dynamic Updates. If you must run with this service it should be secured. BIND provides Access Control Lists (ACLs) which allow simple IP address protection but this is probably not adequate unless you can secure the IP addresses, that is, all systems are behind a firewall/DMZ/NAT or the updating hosts are using private IP addresses.
TSIG/TKEY If all other solutions fail DNS specifications (RFC 2845 - TSIG and RFC 2930 - TKEY) provide authentication protocol enhancements to secure these Server-Server transactions.
TSIG and TKEY implementations are messy but not too complicated simply because of the scope of the problem. With Server-Server transactions there is a finite and normally small number of hosts involved. The protocols depend on a shared secret between the master and the slave(s) or updater(s). It is further assumed that you can get the shared secret securely to the peer server by some means not covered in the protocol itself. This process, known as key exchange, may not be trivial (typically long random strings of base64 characters are involved) but you can use the telephone(!), mail, fax or PGP email among other methods.
The shared-secret is open to brute-force attacks so frequent (monthly or more) changing of shared secrets will become a fact of life. TKEY allows automation of key-exchange using a Diffie-Hellman algorithm but starts with a shared secret! TKEY appears to have very limited, if any, usage.
2.3.5 Server-Client (DNSSEC)
The classic Remote Poisoned cache problem is not trivial to solve simply because there may be an infinitely large number of Remote Caches involved. It is not reasonable to assume that you can use a shared secret.
Instead DNSSEC relies on public/private key authentication. The DNSSEC specifications (RFC 4033, RFC 4034 and RFC 4035 augmented with others) attempt to answer three questions:
- Authentication - the DNS responding really is the DNS that the request was sent to.
- Integrity - the response is complete and nothing is missing or changed.
- Proof of non-existance - if the DNS returns a status that the name does not exist (NXDOMAIN) this response can be proven to have come from the authoritative server.
 Chapter 3 - Reverse Mapping
Chapter 3 - Reverse Mapping
 Main Contents
Main Contents
Problems, comments, suggestions, corrections (including broken links) or something to add? Please take the time from a busy life to 'mail us' (at top of screen), the webmaster (below) or info-support at zytrax. You will have a warm inner glow for the rest of the day.