Failover Strategies
I don't like short TTLs for the reasons listed here. In fact, I consider them to be evil. Further, I cannot think of any reason, except perhaps failover, for using them. Perhaps I lack the imagination, so if readers could suggest some other compelling reasons I would be eternally grateful.
The motivation of this note, therefore, was to see whether short TTLs had a useful role to play in failover. Failover is defined to be the process of moving a user (application) from one IP to another in the event that a server or the access route to a server fails. Clearly it is desirable that this failover process should happen as quickly as possible. Based on the results of some experiments the conclusion is that multiple RRs are a better failover strategy in the cases noted below and will result in a failover occuring between 100% and 1500% faster than a short TTL strategy.
Two strategies for failover are considered:
Short TTLs - in many cases we are seeing TTLs in the 0 (no caching) to 5 second range as site providers seek to keep sites on the air as much as possible - especially if revenues are at stake - by providing an up-to-the-second IP address and using a short TTL to try and force caches to be updated frequently.
When used in this way it is assumed that some automagical process monitors the health of the target service and modifies the DNS records in real-time.
However, unless the site monitoring process also includes all possible network routes from the user to the site it cannot handle temporary/permanent failures occuring anywhere in the access network. Assuming that a multiple RR strategy uses separate geographic locations (which will necessarily use different network routings), a multiple RR strategy will also compensate for such outages.
Multiple A/AAAA RRs. In this case the service is replicated in two or more locations and all the available IP addresses are published in the authoritative name servers for the domain. Short TTLs have no role to play with a multiple RR strategy and therefore normal (long) TTLs can be used.
In examining the best strategy two environmental assumptions are made:
The service for which failover is required is TCP based, for example, HTTP, HTTPS or FTP and is initiated from a web browser (MSIE or Mozilla family). This assumption is made since it both represents the most common case and because TCP error recovery methods are defined within the protocol (whereas UDP recovery is typically application specific).
The clients accessing the services are based on Microsoft's Windows series of OSes. Fact of life - over 90% are. While not measured on non-windows platforms it is reasonable to expect this assumption is not particularly relevant since TCP recovery strategies are defined by the protocol and therefore should be platform independent.
If neither of the above assumptions fits the case that is of interest to the reader then the conclusions below may be of little relevance. An optimal failover strategy will need to be reviewed in the application-specific context and with all the case-specific variables taken into consideration.
Note: The note also ignores completely email failover which has its own well established mechanism using the MX preference field.
Some Good News - Some Bad News
Before moving forward it is important to understand the process by which an end user application - in this case a web browser - obtains the IP address of a resource. Figure 1 illustrates this process.
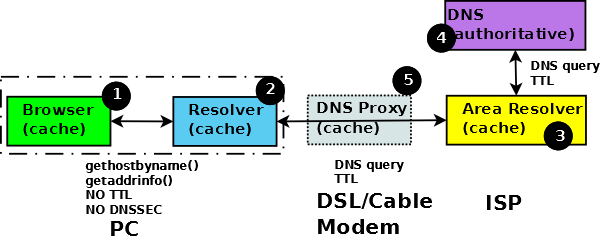
Figure 1 Caching effect in browsers
The browser requests the IP address typically using a POSIX standard resolver library function (1) - either gethostbyname() or the newer version getaddrinfo(). The local resolver (2) on receipt of the request initiates a standard DNS query to its locally defined DNS (3) - typically located at a service provider - which, being a recursive DNS, will initiate one or more DNS queries to the DNS infrastructure finally resulting in a query to the domain owners name servers (4).
The response paths 4->3 and 3->2 contain the complete DNS RRs, including the TTL data, which answer the query. The library function response (path 2->1) is not specified to contain TTL data (even proprietary MS DNS library calls have similar limitations) but does contain an array of all the values (IP addresses) that satisfy the initial function call.
The DNS RR TTL information at point (1) is effectively lost whereas multiple A/AAAA data is not. The browser - in order to speed up performance - maintains a cache of results, which - in the abscence of any other information - is timed out after 30 minutes in the case of MS Internet Explorer and 1 minute in the case of the Mozilla family (configurable in both cases).
Note: Windows resolvers since XP and 2003 maintain a local cache at (2) which has no effect on the points made in this note but may reduce the number of external DNS queries.
Since we assume that our browsers (both Mozilla Firefox and MS Explorer) are operating on a windows TCP/IP stack we now need to consider what happens when we fail to access the site:
The specs for MS indicate the following error recovery times. On intial connection (when sending SYN) the MS TCP/IP stack tries three times with timeouts of 3 + 6 + 12 seconds = 21 seconds. If the site fails during an established TCP connection the MS TCP/IP stack tries 5 times with an initial timeout based on the RTT of the connection, assuming the RTT starts at 0.5 seconds the retries will timeout after 1 + 2 + 4 + 8 = 15 seconds.
On completion of the TCP retry process each browser then initiates its own retries.
Multiple A/AAAA RRs. Experiments showed a failover time of approximately 1 minutes 30 seconds to an alternate site when using multiple A (or AAAA) RRs for both browser families. Both browsers then stayed with the failed-over site and gave normal performance thereafter.
Single IPs with a short TTL. Experiments showed it took 2 minutes for MSIE to finally give up and with its browser cache it would be a worse-case 28 minutes before a further attempt would be made to read the DNS record irrespective of its TTL value. In the case of Firefox it took approximately 3 minutes to finally admit defeat. But a further retry will cause a re-read of the DNS RR so a short TTL would be effective if it replaced the IP address.
Note: When a web proxy or caching system is involved things can get a little more complicated. We have received reports that some web proxies/caches do not handle multiple A/AAAA RRs correctly. Needless to say the excellent Open Source Squid proxy does handle multiple A/AAAA RRs perfectly.
Summary
Using a short TTL to accomplish quick failover for a browser based application is a flawed and ineffective strategy. Multiple A (or AAAA) RRs will achieve a timely failover irrespective of its TTL value which consequently could be set to a high value thus reducing dependence, and load, on the DNS hierarchy.
Problems, comments, suggestions, corrections (including broken links) or something to add? Please take the time from a busy life to 'mail us' (at top of screen), the webmaster (below) or info-support at zytrax. You will have a warm inner glow for the rest of the day.